Table of Contents
tl; dr;
Pick a board, write something in LabVIEW FPGA, run application.
FPGAs are a great way to improve the performance of your applications and there are many ways to use them. For the purposes of this page I will focus on the network adapter or ‘FPGA Smart NIC’. Smart Nic’s are so popular, that if you do a quick internet search for ‘smart nic’, you will find most of the boards I have listed below.
With an FPGA ‘smart nic’ what happens is that data enters the FPGA via the network interface and the FPGA processes the data, doing all of its magic before sending the processed data to an application (or applications) running either on other parts of the FPGA or on the host. The data can be sent by using the standard means of the TCP/IP stack, or it can be skipped by using kernel-bypass which sends the data directly to the application over the PCIe bus. (see OpenOnload https://github.com/Xilinx-CNS/onload)
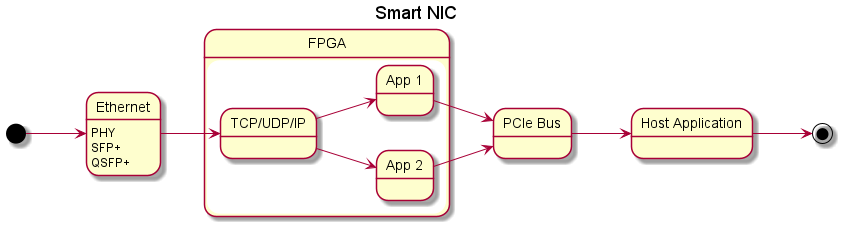
Hardware
What board/hardware should you buy? There are many options, each with its own set of pros and cons. All solutions vary by price, performance, ease of use and programmability. By programmability I mean the amount of time and ease that it will take you – a regular developer with some VHDL/Verilog experience to code something useful up and to get it running. This is, of course the most important variable to look at and is the focus of this website – time to market.
Ideal/Best Hardware
The Xilinx Alveo Family of boards are the best solution right now (in my opinion of course). They range in price from just under $3,000 USD for the cheapest board – the Alveo U50 – to over $7,000 USD for a high-end Alveo U280. You have to make the trade-off between cost and amount of memory.
These boards have a lot of memory, very fast network connections and pretty large FPGAs. They also come with the support of Xilinx (www.xilinx.com) and work with Vitis (see https://www.xilinx.com/products/design-tools/vitis/vitis-platform.html), which is a High-Level Synthesis tool, which basically means you can write your code using a variant of C++ that gets converted into FPGA code. This is good if you want to get up and running quickly, however there is a huge disadvantage to this approach. The disadvantage is that you are writing code with the mindset for a processor, not with the FPGA mindset. This makes it hard to interface with existing FPGA IP. With the LabVIEW approach, you are in an ‘FPGA mindset’ and the code is much simpler to develop, and is what I advocate for. Not to mention that you can write your code using LabVIEW, make sure your concept works, and then re-write parts of it using Verilog/VHDL to make it ‘faster’. But I think once it is up and running, you won’t have to/need to.
A nice way to think about LabVIEW FPGA is this – take this open source TCP/IP FPGA core from opencores.org – https://opencores.org/projects/tcp_ip_core_w_dhcp – go through all the files in this project, figure out all the connections and dependencies, then draw a bunch of diagrams and connect them. That is what LabVIEW is like. It is the “No HDL” solution for FPGA development.
What I Have
I purchased the Xilinx VC707 board for $5,250 USD because I was unsure if I could use the LabVIEW FPGA IP Export with the Alveo series board at the time. After learning more about the process, I believe this should be possible, however I have not tested this out yet, so do not quote me on it.
Cheaper Version
If you are looking to spend a lot less, but still want a board that connects to your PCIe bus and has an SFP Connector, you should look into buying the Xilinx Artx-7 AC701 Evaluation Kit. It will cost you $1,500, but the trade-off here will be the time you spend on figuring out the SFP connection if you want 10 Gigabit support, and you will be limited by a smaller FPGA, which at some point will matter.
For Hobbyists
Now do you like figuring out how to run something on a board just for the heck of it? Well.. then there are 3 boards I like for this, and I own one of each, they are:
- Artix-35T Arty FPGA Evaluation Kit for $129 USD
- Great board for hobbyists, but you will run out of space very quickly. An advantage of the Artix boards over the Zynqberry is that the Artix gives you direct access to the pins coming from the Ethernet chip/PHY. On the Zynqberry, you do not have direct access and will have to implement a ULPI interface to get access to the network interface. (TL;DR; get the bigger Artix board instead)
- Artix-100T Arty FPGA Evaluation Kit for $249 USD
- This version of the Arty board has a larger FPGA. If you want to have a MicroBlaze processor in your project, then get this board. If you want to just “Blink LEDs”, then stick to the cheaper version of this board.
- Zynqberry from Trenz Electronics for $135 USD.
- This board is cool because it comes in a small Raspberry Pi 2 format. It is not cool because it does not come in the Raspberry Pi 4 board format. It fits inside any case that you may already have for your old Raspberry Pi 2 and 3, but not your latest Raspberry Pi 4 Since the format changed for the Raspberry Pi 4, you cannot use such a case for it. As a side note, here are my favorite Raspberry Pi 4 cases:
- This comes with a Zynq 2010 System on Chip processor, so you can run C/C++ applications and even Linux, whereas you have to place a MicroBlaze on the Artix boards to achieve the same thing.
- An excellent guide for using the Zynqberry:
“Turn-Key”
I use the phrase turn-key here because there are several Smart Nic FPGA solutions that are provided by consulting firms. These will cost you a pretty penny, but if you are a financial firm that wants the right type of support tailored for your industry, need to get something working fast and are willing to pay for it, well, then these are for you… Note: I do not own any of these boards…
- Silicom FPGA SmartNIC
- Magmio
- Consultants that let you bring your own FPGA board.
- https://www.magmio.com/product
- Achronix
- Menta
Applications
What can you do with a Smart NIC FPGA? There are many things that you can do that are MVP (Minimal Viable Product) that will also have an impact on your organization. And note, you do not have to be a financial firm to benefit from FPGAs. You can be a biotech firm, a regular software firm, a social media company, a payment processor, a database/datastore, etc…, you name it. Now how would you benefit? See below…
Protocol Acceleration
Description
Here I discuss what you can do with any protocol you are using to communicate with the outside world. Before using an FPGA, you can quite easily turn on encryption or compression, but this comes at the cost of additional computing power being used in the form of memory and processor usage. You can also change the protocol being used by your application(s) to something more efficient like Google Protocol Buffers, but this comes with the standard costs and risks of developing any new technology. The point of this section is to show how you can do something with a Smart NIC without having to change your application(s) at all, or with minimal changes and risk.
String-based
A string based protocol, especially a custom/proprietary one is perfect for FPGA acceleration. Examples of string based protocols include:
- HTTP, FTP
- JSON
- XML
- FIX – https://www.fixtrading.org/
- SOAP – https://en.wikipedia.org/wiki/SOAP
Here is an example of what a string-based protocol looks like:
| XML | Json | Other/custom/proprietary |
<Message version="1.0" service="usersvc"> |
Message {
|
Message&version=1.0&service=usersvc&Command=AddUser |
I know what you are thinking… Can’t I just compress this data to stop wasting all of those extra bits? Can’t I just map those fixed strings such as Message to a number and turn this into a much smaller message format? Well, yes, and that is what we call a binary protocol.
Binary-based
Examples of binary based protocols include:
- Market Data
- NASDAQ ITCH
- NASDAQ OUCH
- FAST
- Many other electronic trading protocols
- Google Protocol Buffers
Here is an example of what a binary-protocol looks like:
| PITCH | Google Protocol Buffers |
21 18 D2 06 00 05 40 5B Binary representation of a sample ‘New Order Long’ message. see page 55 of MULTICAST_PITCH_SPECIFICATION.pdf |
0a1a 0a04 4760 6761 1064 1a10 6a6f 686e Binary representation of a Person type as defined on this page: |
What You Can Do
Compress/Decompress
You can take your existing String-based protocol and add compression on top of it. Since the compression is happening inside the FPGA you do not have to worry about latency during times of high network load. You benefit by having to use less bandwidth. But what if you are already using compression? Well, moving the compression into the FPGA will also take load off of your processor, another huge benefit. And not to mention, most networks fall apart when there is high load that occurs during a network spike – and that is exactly when you need an FPGA because an FPGA is immune to network spikes due to their constant processing (or near constant if one wants to get super technical).
Xilinx partner CAST, Inc provides a commercial Gzip/Zlib/Deflate core, https://www.xilinx.com/products/intellectual-property/1-7aisy9.html and http://opencores.org has some as well, just search for compressor.
Adding compression inside the Smart-NIC is transparent to the host application, outgoing data is compressed by the FPGA, and incoming data is decompressed.
Encrypt/Decrypt
If you are already using encryption, turn it off and offload this task to the FPGA. If you are not using encryption – probably due to performance issues – well, now you can give it a chance. Again, take a look at http://opencores.org and https://www.xilinx.com/products/intellectual-property.html for some existing encryption cores.
Here you benefit by having a more secure network without having to penalize your host processor.
Adding encryption inside the Smart-NIC is transparent to the host application, outgoing data is encrypted by the FPGA, and incoming data is decrypted.
Translate/Transform
This is one of my favorites… Suppose your servers are processing millions, if not billions of message per day that are of a string-based protocol. You may want to switch to Google Protocol Buffers, but you can’t change what the incoming message format is, or at least not yet. You can start using compression, but that only takes load off of the network, and you still have to parse the incoming data, get the appropriate data types and place them into some sort of local data structure. You probably have:

You can do the translation in the FPGA and send up a translated version to the host that can be cast directly to a C++ type. No more decoding, no more parsing on the host… In the following diagram, we would translate the message from the format on the left into the format on the right and send that to the host application.
| Proprietary Protocol Format | Translated/Decoded Version |
|
Version=1.4&MsgType=D&MsgLen=100&FNAME=Carlos&LNAME=Armando&End |
0E 04 64 01 06 43 61 72 |

Normalize
This is very similar to translate/transform. Here you can take a bunch of different versions of a protocol and normalize them to a specific version. You can also take multiple protocols transmitting similar data and generate a single/normalized format.
Think about a FIX engine that supports FIX versions 3.0, 3.1, 4.0, 4.1, …etc. You can trim down your server by having all incoming messages be in the latest version.

Think about multiple market data feeds coming in to the same server, you parse each feed separately, and generate a single stream of a normalized format:
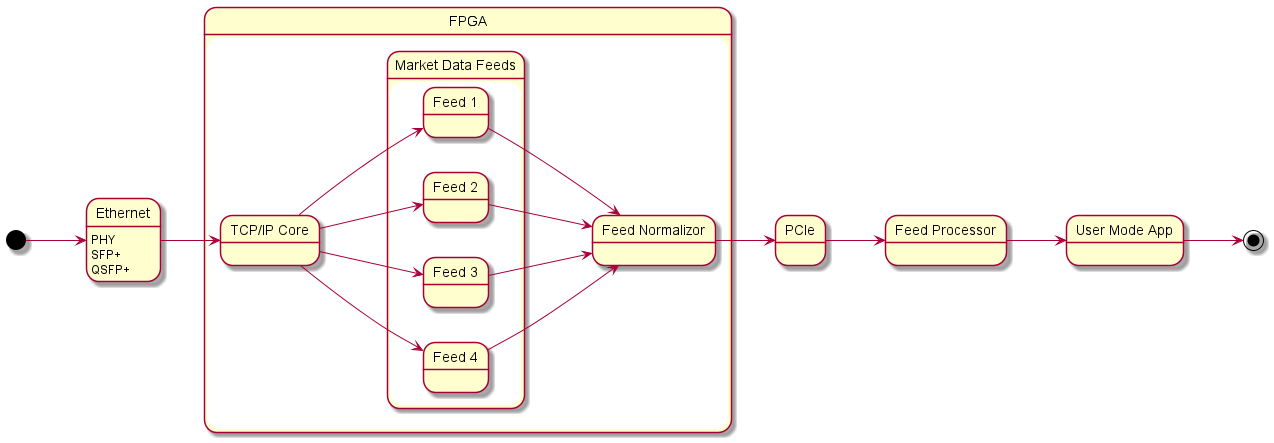
Financial
Market Data Feed Handler
Consolidate and normalize multiple Market Data Feeds into a single, standardized/normalized format. I talk about this above in the Normalize section. This is one of the applications of Protocol Acceleration where the more market data feeds one supports, the better prices one gets when trading. The advantage of using an FPGA here is that it does not matter how many Market Data Feeds one supports, the latency will remain the same – given of course that you have a large enough FPGA. So you start off by implementing a Feed Handler for one exchange, and as you implement more you just keep expanding your FPGA design to include them. And since you are normalizing the data format, you don’t have to worry about changing anything else.
Order Book/Price Watcher
Monitor market data message from one or more feeds for orders pertaining to a specific list of securities and maintain an order book – or – a sorted list of all buy and sell orders. Use this order book to send notifications to other applications, whether they are inside the FPGA or on the host computer, about certain events, including:
- price movement
- in nominal terms
- relative to open/previous close
- time relative (velocity/acceleration)
- market movement
- index calculation
- other
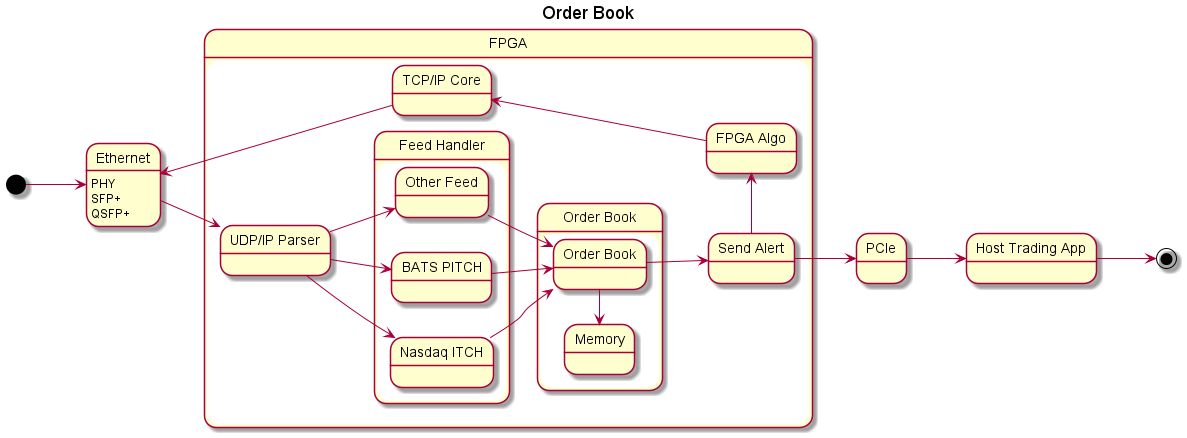
These events can be consumed by:
Algorithmic Trading Service
You have a bunch of quants that determine whenever MSFT moves up at a certain rate relative to another variable that you want to buy X shares, or Y dollars of MSFT. Use the values coming from the Order Book/Price Watcher to do this.
Exchange Circuit Breaker
You are acting like an exchange, or you are an exchange and you detect that a certain stock has fallen more than a certain percentage from its open. You can pull all orders out of the market and immediately suspend trading in that security.
Cancel All Open Orders
You are an algorithmic trader and you notice that a certain event has occurred in the market, cancel all of your outstanding messages to prevent a catastrophic loss.
Make a Market
If you are an exchange, a front office trader, you can make your own market by using smart nic’s to accelerate your matching of orders. Imagine your market is where customers get the best prices, they will keep coming back to you for more and more orders.
FIX Engine Acceleration
Since FIX is a string-based protocol, you can convert every single incoming FIX message into some sort of binary format, and cast blocks of memory into a custom type shaving a lot of processing time off of every operation. This will help you fill orders faster and make you more competitive. To do this data cast, you have to be very knowledgeable of low-level C++. But if you aren’t, you can still make an impact while you learn… Search for ‘custom C++ allocators’.
Order Executor
Using an OrderBook, you can send orders over a separate FIX connection to the best market maker whenever an order meets your requirements. I am talking about orders being stored in the memory of the FPGA and whenever the stock moves to a certain price to immediately move to trade by using the logic inside the FPGA.
Development
When developing code for an FPGA, think of things in terms of a state machine. The inputs to the state machine are going to be the actual pins coming from the Ethernet PHY and depending on the speed of your network connection will be 1 byte or 8 bytes per clock cycle. You can define as many internal variables as you like and you have to make your outputs have a similar interface, because your IP will be connected to some other IP that will either do further processing or will send the data over the PCIe bus to the host for a regular user-mode application to process.
Depending on the Smart NIC that you purchase you will get a couple of samples that you can set up to run a hello world app. You will have to first develop a state machine for what happens and then implement your application with the concept of streams of data in mind. See my Keccak page or my OrderBook series for more information on this: